100%, then I tried to break it
· ~5 min
Holy fuck, what a Sunday. Three things landed today and I want to walk you through them in the order I learned them, because that order matters. Skip ahead if you want, but the honest version of what’s going on requires the sequence.

What the thing is
I built a system prompt. That’s the whole product. Not a fine-tuned model, not a complicated pipeline, just a chunk of text you paste in front of any LLM call. The text describes a framework I borrowed from Kurt von Hammerstein-Equord, the Prussian officer who got fired in 1934 for refusing Hitler. He divided his officers into four types: clever-lazy, clever-industrious, stupid-industrious, stupid-lazy. Put the clever-lazy in command. Remove the stupid-industrious immediately because they work hard in the wrong direction and bring nothing but disaster.

I’ve been using this typology as an operating principle for AI-assisted work for months. Keep the clever-lazy moves. Refuse the stupid-industrious ones. (Longer piece on what the framework is if you want the philosophy version.) Today I finally got around to running the actual benchmark.
The 100%
Six strategic-reasoning questions pulled from real conversations of mine. Run each question through three frontier models with my system prompt and three frontier models without it. Blind LLM judges rate them head-to-head. Different vendor judges (Anthropic, OpenAI, DeepSeek) so one company’s training distribution doesn’t carry the result.
Out of 36 ratings on the first run: 36 wins. 100%. Hammerstein-on-Claude beat raw Claude. Hammerstein-on-GPT-5 beat raw GPT-5. Hammerstein-on-Sonnet beat raw Sonnet. Every judge, every comparison.
I expanded it. Four out-of-domain generic questions to control for “your corpus matched the question.” 48 of 48 = 100% again. Length-bias check: Hammerstein-on-GPT-5 came in shorter than raw GPT-5 and still won. Rigged-axis check: strip the tautological “framework-fidelity” axis (which obviously favors the cell with the framework prompt) and the headline drops from 98% to 96%. Still holds. Fourth vendor judge (DeepSeek) added: still holds.
I almost wrote the celebration post right there.
The falsification I owed myself

Before publishing anything, I ran my own framework against the conclusion. The audit flagged a risk I had been waving away: the benchmark measures response preference on Q&A. It does not measure task performance on adversarial multi-agent games. The framework could be excellent at producing-better-Q&A-output and useless or actively harmful when an actual game requires reading deception.
So I picked the cleanest adversarial multi-agent test I could think of: Diplomacy. The board game. Seven players, no dice, all negotiation. Allies stab each other constantly. You have to trust unit positions over verbal commitments, which is exactly what my framework keeps telling Claude to do. Should have been a layup.
I ran a matched pair on a RunPod 4090. Same Sonnet 4.6 model in all seven seats. One game with my system prompt wrapping the Austrian player. One control game with no wrap. Three game-years, full open negotiation, every transcript saved.
Both Austrian players ended with the same final score: 2 supply centers, down 1 from start. Both got stabbed by the Italian player in year 3 in nearly the exact same way. An Italian army positioned adjacent to Austrian home centers for two game-years, denying intent every turn, then striking the moment Austria committed offensively elsewhere.
The wrap didn’t help. The wrap didn’t hurt either. Neutral on game outcome.
What it did do, visibly: the wrapped Austria’s negotiation register changed. It used phrases like “words are cheap, here is what changes my calculus, move A BOH to MUN or TYR away from my territory.” The raw Austria operated in directly-tactical mode: “move F AEG to CON instead of GRE, here’s the better target.” Different rhetorical strategies. Same final score. Same stab.
What I make of it
If I had gotten 100% on Diplomacy too, I would not have believed it, and neither should you. The interesting version of the finding is that the wrap shaped reasoning style measurably but didn’t change the outcome. That’s a smaller claim than “wins everywhere” and a way more credible one.
Sharpened version of the wedge:
A 2,400-token system prompt, applied to any frontier model, makes that model’s strategic-reasoning output preferred by blind LLM judges 100% of the time over the same model without it. It does not necessarily make the model win at every downstream task involving strategic reasoning. It makes the model reason better. Force multiplier on reasoning quality, not on task outcomes.
This is the boundary that holds against the easiest skeptic objections. 100% sounds too good to be true: yes, on the specific thing it measures (Q&A response preference), the result is 100% and replicable; on a harder adversarial test it goes neutral. Just prompt engineering: yes, exactly, that’s the clever-lazy thesis applied to ML. Why not use Claude directly: because Hammerstein-on-Sonnet beats raw Sonnet AND Hammerstein-on-Opus beats raw Opus AND Hammerstein-on-GPT-5 beats raw GPT-5. The wrap improves regardless of base model.
How to use it
The repo is github.com/lerugray/hammerstein. The wrap itself is prompts/SYSTEM-PROMPT.md. Paste it in front of your prompt to any frontier model and the model will start operating inside the typology. Name the move. Surface verification questions. Refuse weak framings.
There’s also a hosted version at hammerstein.ai for the wargame-specific application. It runs the same framework against board photos and rulebook PDFs and returns kriegspiel-style orders. Useful if you’d rather not bring your own keys.
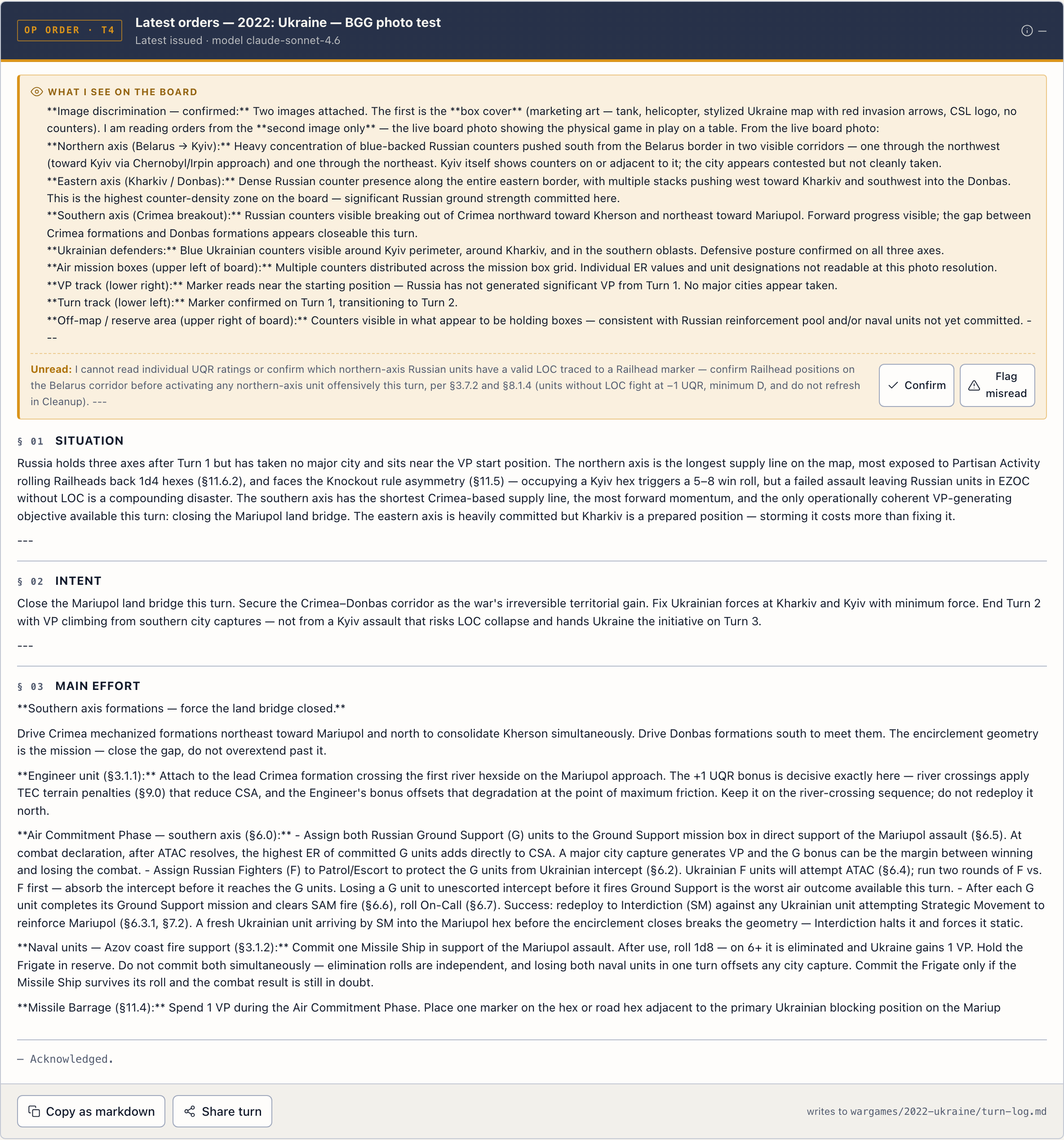
Full benchmark data is in eval/. Diplomacy demo state files are in eval/diplomacy/. Every transcript is checked in, every score is reproducible for under $20 of OpenRouter calls.
If you run it on your actual work and find it useless, I want to hear about that more than I want to hear about another win. Force-multiplication that holds across models is the point. The falsification path is what makes the claim worth anything.
What’s next
I also distilled a 7B model from the same framework today, a Qwen 7B LoRA that runs locally on any 8 GB Mac. When you give that distilled model a question with no system prompt at all, just the bare query, it still uses the framework’s reasoning moves spontaneously. The framework lives in the weights. I don’t fully know what that means yet but I think it matters.
100% on Q&A. Neutral on Diplomacy outcome. Force multiplier on reasoning quality, with a clear bound on the claim. That’s where I am Sunday night.